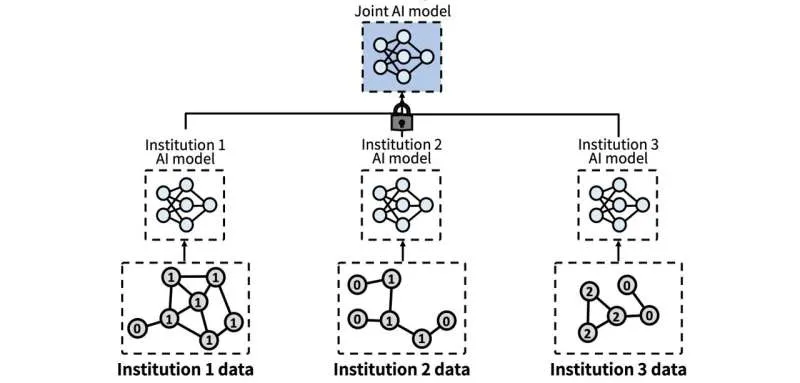
Проблема сохранения конфиденциальности персональных данных, таких как медицинские записи или финансовая информация, долгое время затрудняла их агрегацию для обучения искусственного интеллекта. Однако новое исследование предлагает решение, позволяющее нескольким учреждениям совместно обучать общую модель ИИ, не раскрывая при этом свои исходные данные. Этот подход, известный как федеративное обучение, позволяет использовать преимущества обучения на разнообразных данных, сохраняя при этом строгую защиту конфиденциальной информации.
Каждое учреждение обучает свою локальную модель ИИ на собственных данных. Затем на центральный сервер передается только информация об обученной модели, а не сами данные. Это позволяет создать высокопроизводительную 'Совместную ИИ-модель'.
Основная сложность федеративного обучения возникает на этапе оптимизации совместной модели под специфику каждого учреждения. ИИ может стать излишне адаптированным к данным конкретного учреждения, что делает его уязвимым к новым, ранее не встречавшимся данным. Эта проблема, известная как локальная переоптимизация, приводит к снижению общей производительности ИИ.
Исследовательская группа под руководством профессора Чан Ён Парка из Департамента промышленной и системной инженерии представила метод, который фундаментально решает проблему деградации производительности при федеративном обучении. Новый подход значительно повышает способность моделей ИИ к обобщению.
Для решения проблемы локальной переоптимизации команда предложила использовать синтетические данные. Из данных каждого учреждения были извлечены ключевые и репрезентативные признаки, на основе которых сгенерированы виртуальные данные, не содержащие личной информации. Эти синтетические данные затем использовались в процессе дообучения. В результате каждое учреждение может развивать свою специализацию, основываясь на собственных данных, не раскрывая при этом конфиденциальную информацию, и одновременно сохранять широкий охват знаний, полученный в ходе совместного обучения.
Этот метод оказался особенно эффективным в областях с высокими требованиями к безопасности данных, таких как здравоохранение и финансы. Он также продемонстрировал стабильную работу в динамичных средах с постоянным появлением новых пользователей и продуктов, например, в социальных сетях и онлайн-торговле. Исследование показало, что ИИ может поддерживать стабильную производительность даже при изменении характеристик данных или добавлении новых участников в совместное обучение.
«Наше исследование открывает новый путь для одновременного обеспечения экспертизы и универсальности ИИ каждого учреждения при сохранении конфиденциальности данных», — отметил профессор Парк. «Это станет значительным подспорьем в сферах, где совместное использование данных имеет решающее значение, но при этом важна безопасность, например, в медицинском ИИ и системах обнаружения финансовых мошенничеств».











