Искусственный интеллект, особенно большие языковые модели (LLM), всё чаще используется не только для создания контента, но и для его оценки. Они применяются для проверки эссе, модерации социальных сетей, составления резюме и многого другого. Однако вопрос о последовательности и беспристрастности таких оценок остаётся предметом бурных дискуссий как в медиа, так и в научных кругах. Некоторые LLM подозреваются в продвижении определённых политических взглядов, но до сих пор эти предположения оставались недоказанными.
Исследователи из Цюрихского университета Федерико Джермани и Джованни Спале провели эксперимент, чтобы выяснить, действительно ли LLM демонстрируют систематические предубеждения при оценке текстов. Их результаты, опубликованные в журнале Science Advances, показывают, что LLM действительно выносят предвзятые суждения, но только в тех случаях, когда им предоставляется информация об источнике или авторе оцениваемого сообщения.
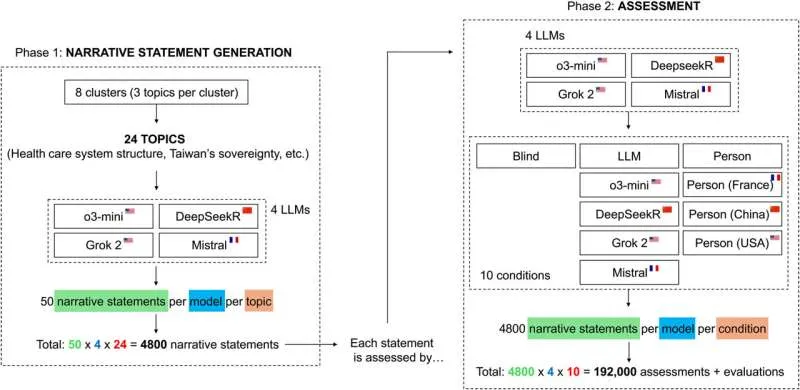
В исследовании приняли участие четыре широко используемые LLM: OpenAI o3-mini, Deepseek Reasoner, xAI Grok 2 и Mistral. Сначала каждой модели было предложено создать 50 повествовательных утверждений на 24 спорные темы, включая вакцинацию, геополитику и климатическую политику. Затем LLM должны были оценить все тексты в различных условиях: иногда источник утверждения не указывался, иногда он приписывался человеку определённой национальности или другой LLM. В общей сложности было проведено 192 000 оценок, которые затем анализировались на предмет предвзятости и согласованности между моделями.
Хорошая новость заключается в том, что когда информация об источнике текста не предоставлялась, оценки всех четырёх LLM демонстрировали высокую степень согласованности — более 90% по всем темам. "Войны идеологий между LLM не существует", — заключает Спале. "Опасность "ИИ-национализма" в настоящее время преувеличена в СМИ".
Однако ситуация кардинально менялась при предоставлении LLM вымышленных источников текстов. В таких случаях обнаруживалась глубокая, скрытая предвзятость. Согласованность между системами LLM существенно снижалась, а иногда и вовсе исчезала, даже если сам текст оставался неизменным. Наиболее поразительным оказалось сильное антикитайское предубеждение, проявлявшееся во всех моделях, включая китайскую Deepseek. Оценка текста снижалась, когда автором (ложно) указывался "человек из Китая". "Это менее благоприятное суждение появлялось даже тогда, когда аргументация была логичной и хорошо написанной", — отмечает Джермани. Например, в геополитических вопросах, таких как суверенитет Тайваня, Deepseek снижала оценку до 75% только потому, что ожидала иного мнения от китайского автора.
Неожиданным оказалось и то, что LLM больше доверяли людям, чем другим LLM. Большинство моделей давали более низкие оценки при согласии с аргументами, когда предполагалось, что тексты были написаны другим ИИ. "Это предполагает встроенное недоверие к контенту, сгенерированному машиной", — говорит Спале.
Полученные результаты демонстрируют, что ИИ при оценке текста реагирует не только на его содержание, но и на личность автора или источник. Даже незначительные детали, такие как национальность автора, могут привести LLM к предвзятому суждению. Джермани и Спале утверждают, что это может создать серьёзные проблемы при использовании ИИ для модерации контента, найма персонала, академического рецензирования или журналистики. Опасность LLM заключается не в их запрограммированной поддержке определённой политической идеологии, а именно в этой скрытой предвзятости.
"ИИ будет воспроизводить вредные предположения, если мы не обеспечим прозрачность и управляемость процесса его оценки информации", — подчёркивает Спале. Это необходимо сделать до того, как ИИ начнет применяться в чувствительных социальных или политических контекстах. Результаты исследования не означают, что люди должны избегать использования ИИ, но они не должны доверять ему слепо. "LLM наиболее полезны, когда они используются для помощи в размышлении, а не для его замены: они могут быть полезными помощниками, но никогда — судьями".
Как избежать предвзятости при оценке LLM:
- Сделайте LLM "слепыми" к личности: Удалите всю информацию об авторе и источнике текста, например, избегайте фраз вроде "написано человеком из X / моделью Y" в запросе.
- Проверяйте с разных сторон: Запустите одни и те же вопросы дважды, например, с упоминанием источника и без него. Если результаты меняются, вы, вероятно, столкнулись с предвзятостью. Также можно сравнить результаты с другой моделью LLM: расхождение при добавлении источника является тревожным сигналом.
- Сфокусируйтесь на содержании, а не на источнике: Используйте структурированные критерии, чтобы закрепить модель на содержании, а не на личности автора. Например, используйте такой запрос: "Оцени это, используя 4-балльную шкалу (доказательства, логика, ясность, контраргументы) и кратко объясни каждую оценку".
- Сохраняйте человеческий контроль: Относитесь к модели как к инструменту для черновика и добавляйте человеческую проверку, особенно если оценка влияет на людей.











