Разработана инновационная технология искусственного интеллекта, которая позволяет автомобилям с камерами точнее воспринимать окружающее пространство. Этот новаторский подход использует геометрическое понятие точки схода — художественный прием, передающий глубину и перспективу на изображениях.
Профессор Кёндон Джу и его команда из Высшей школы искусственного интеллекта UNIST представили VPOcc — новую ИИ-платформу, которая применяет точку схода для уменьшения расхождений между 2D и 3D информацией как на уровне пикселей, так и признаков. Этот метод решает проблему искажения перспективы, присущего входным данным с камер, обеспечивая более точное понимание сцены.
Автономные транспортные средства и роботы распознают окружающую среду в основном с помощью камер и лидарных датчиков. Хотя камеры более доступны по цене, легки и способны захватывать богатую информацию о цвете и форме по сравнению с лидарами, они также создают значительные проблемы из-за проецирования трехмерного пространства на двумерные изображения. Объекты, находящиеся ближе к камере, кажутся крупнее, а удаленные — меньше, что может приводить к ошибкам, таким как пропуск обнаружения далеких объектов или чрезмерное выделение близлежащих областей.
Для решения этой задачи исследовательская группа разработала ИИ-систему, которая реконструирует информацию о сцене на основе точки схода — концепции, установленной художниками эпохи Возрождения для изображения глубины и перспективы, где параллельные линии сходятся в одной точке на горизонте. Подобно тому, как люди воспринимают глубину, распознавая точки схода на плоском холсте, разработанная ИИ-модель использует этот принцип для более точного восстановления глубины и пространственных отношений в видеозаписях с камер.
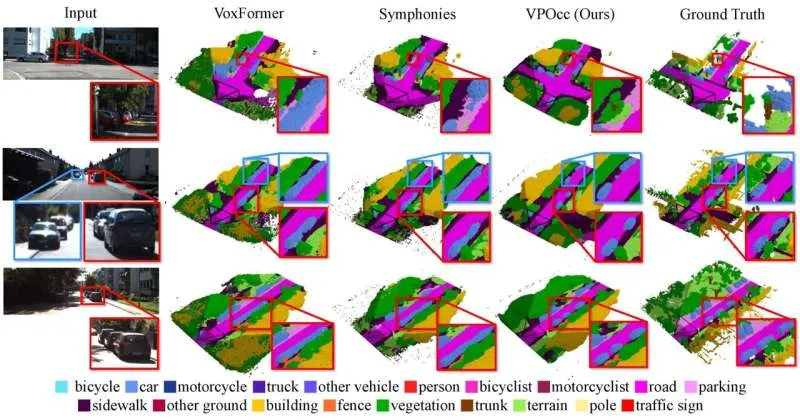
Модель VPOcc состоит из трех ключевых модулей. Первый — VPZoomer, который корректирует искажение перспективы путем деформации изображений на основе точки схода. Второй — VP-guided cross-attention (VPCA), который извлекает сбалансированную информацию из близких и далеких областей посредством агрегации признаков с учетом перспективы. Третий — special volume fusion (SVF), который объединяет оригинальные и скорректированные изображения, чтобы дополнить сильные и слабые стороны друг друга.
Экспериментальные результаты показали, что VPOcc превосходит существующие модели по нескольким бенчмаркам как в точности пространственного понимания (измеренной с помощью средней степени пересечения над объединением, mIoU), так и в точности реконструкции сцены (IoU). Примечательно, что модель более эффективно предсказывает удаленные объекты и различает перекрывающиеся сущности — критически важные возможности для автономного вождения в сложных дорожных условиях.
Это исследование возглавил первый автор, Джунсу Ким, научный сотрудник UNIST, при участии Джунхи Ли из UNIST и команды из Университета Карнеги-Меллона в США. Джунсу Ким пояснил: «Интеграция человеческого пространственного восприятия в ИИ позволяет более эффективно понимать трехмерное пространство. Мы сосредоточились на максимальном раскрытии потенциала датчиков камер — более доступных и легких, чем лидары, — путем устранения их присущих ограничений перспективы».
Профессор Джу добавил: «Разработанная технология имеет широкие области применения не только в робототехнике и автономных системах, но и в картографии дополненной реальности (AR) и за их пределами».
Исследование получило Серебряную награду на 31-й премии Samsung Human Tech Paper Award в марте и было принято к представлению на IROS 2025 (Международная конференция по интеллектуальным роботам и системам). Статья доступна на сервере препринтов arXiv.











