Психологи и специалисты по поведенческим наукам десятилетиями пытаются понять, как люди мысленно представляют, кодируют и обрабатывают буквы, слова и предложения. Появление больших языковых моделей (LLM), таких как ChatGPT, открыло новые возможности для исследований в этой области, поскольку эти модели специально разработаны для обработки и генерации текстов на различных человеческих языках.
Растущее число исследований в области поведенческих наук и психологии стало сравнивать эффективность людей и LLM в выполнении конкретных задач в надежде пролить новый свет на когнитивные процессы, связанные с кодированием и декодированием языка. Однако, поскольку люди и LLM по своей сути различны, разработка задач, реалистично исследующих, как оба представляют язык, может быть сложной.
Исследователи из Чжэцзянского университета недавно разработали новую задачу для изучения репрезентации предложений и протестировали на ней как LLM, так и людей. Их результаты, опубликованные в Nature Human Behaviour, показывают, что при просьбе сократить предложение люди и LLM склонны удалять одни и те же слова, что указывает на общность в их репрезентации предложений.
«Понимание того, как предложения представлены в человеческом мозге, а также в больших языковых моделях (LLM), представляет собой серьезную проблему для когнитивной науки», — писали Вэй Лю, Мин Сян и Най Дин в своей статье. «Мы разрабатываем задачу однократного обучения (one-shot learning task), чтобы исследовать, кодируют ли люди и LLM древовидные составляющие внутри предложений».
В рамках своего исследования исследователи провели серию экспериментов с участием 372 носителей китайского языка, носителей английского языка или билингвов (владеющих как английским, так и китайским языком). Эти участники выполнили языковую задачу, которую затем также выполнил ChatGPT.
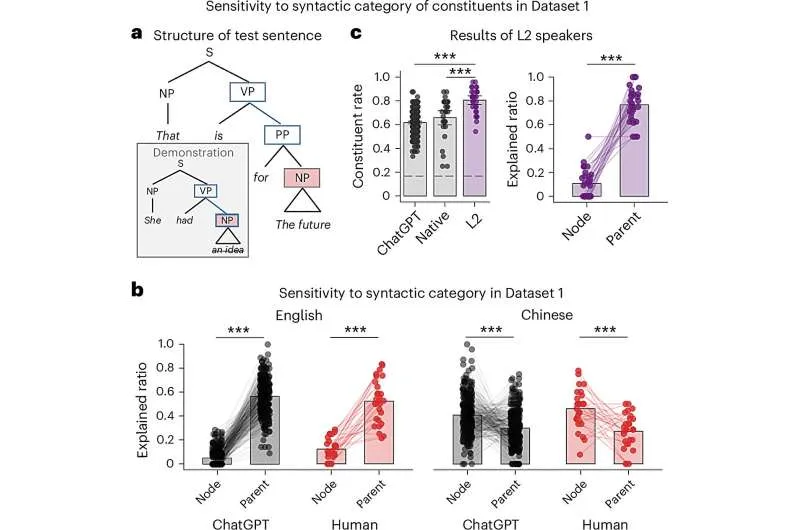
Задача требовала от участников удалить последовательность слов из предложения. В каждом экспериментальном испытании как люди, так и ChatGPT получали одну демонстрацию, затем должны были вывести правило, которому следовали при удалении слов, и применить его к тестовому предложению.
«Участников и LLM просили определить, какие слова следует удалить из предложения», — объяснили Лю, Сян и Дин. «Обе группы склонны удалять составляющие (constituents), а не произвольные последовательности слов, следуя правилам, специфичным для китайского и английского языков соответственно».
Интересно, что выводы исследователей предполагают, что внутренние представления предложений LLM соответствуют лингвистической теории. В разработанной ими задаче как люди, так и ChatGPT имели тенденцию удалять полные составляющие (т. е. связные грамматические единицы), а не случайные последовательности слов. Более того, удаленные ими последовательности слов, по-видимому, различались в зависимости от языка, на котором они выполняли задачу (т. е. китайский или английский), следуя языково-специфическим правилам.
«Результаты не могут быть объяснены моделями, которые полагаются только на свойства слов и их позиции», — писали авторы. «Ключевым моментом является то, что на основе удаленных людьми или LLM последовательностей слов можно успешно реконструировать лежащую в основе древовидную структуру составляющих».
В целом, результаты команды предполагают, что при обработке языка и люди, и LLM руководствуются скрытыми синтаксическими представлениями, в частности древовидными представлениями предложений. Будущие исследования могли бы развить эту недавнюю работу для дальнейшего изучения закономерностей представления языка LLM и людей, используя как адаптированные версии предложенной командой задачи удаления слов, так и совершенно новые парадигмы.











